决策树
Decision Trees
监督学习,判别模型,用于分类和回归问题。分而治之,递归,贪心算法
基于树结构进行决策,从数据特征中推断目标值。
决策树学习的目的:产生一棵泛化能力强(处理未见示例能力强)的决策树
归纳的基本算法是贪心算法(在每一步选择中都采取在当前状态下最好/优的选择),自顶向下来构建决策树。决策树的生成过程中,属性选择的度量是关键。
决策树基本原理
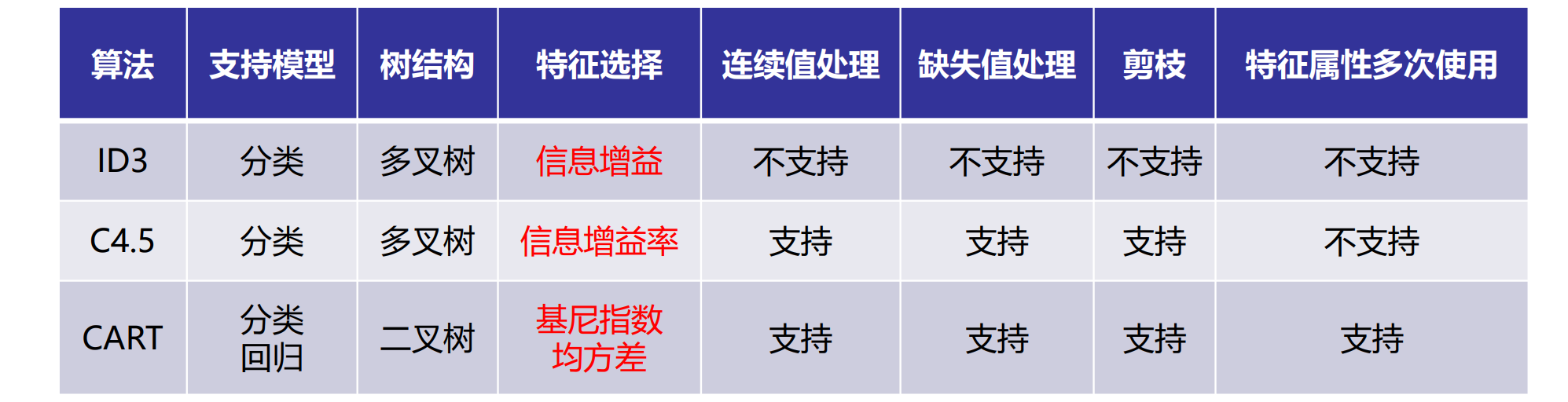
建立决策树的关键,即在当前状态下选择哪个属性作为分类依据,根据不同的目标函数,主要有三种算法
一、 ID3
核心:信息熵。以信息增益为衡量标准,选取最高增益的属性作为分类的标准。
期望信息越小,信息熵越大,样本纯度越低
算法流程
初始化特征集合和数据集合;
计算数据集合信息熵和所有特征的条件熵,选择信息增益最大的特征作为当前决策节点;
更新数据集合和特征集合
重复 2,3 两步,若子集值包含单一特征,则为分支叶子节点
实际计算
- 信息熵:
- 条件熵:
- 信息增益:

缺点
没有剪枝,容易过拟合;只能用于处理离散分布的特征;没有考虑缺失值
二、 C4.5
用信息增益率来选择属性。ID3选择属性用的是子树的信息增益,而C4.5用的是信息增益率;在决策树构造过程中进行剪枝;对非离散数据也能处理;能够对不完整数据进行处理
预剪枝、后剪枝
缺点:C4.5 用的是多叉树,用二叉树效率更高;只能用于分类;使用的熵模型拥有大量耗时的对数运算,连续值还有排序运算;在构造树的过程中,对数值属性值需要按照其大小进行排序;只适合于能够驻留于内存的数据集,当训练集大得无法在内存容纳时,程序无法运行
三、 CART
Classification and Regression Tree
- 目标变量是离散的,称为分类树,基尼指数来选择属性(分类)
- 目标变量是连续的,称为回归树,均方差来选择属性(回归)