聚类
**Clustering **
无监督学习,能够分出点集的算法
使用一个没有标签的数据集,然后将数据聚类成不同的组
一、K-means 聚类
具有一个迭代过程,数据集被分组成若干个预定义的不重叠的聚类或子组,数据点分配给簇,以便簇的质心和数据点之间的平方距离之和最小,在这个位置,簇的质心是簇中数据点的算术平均值
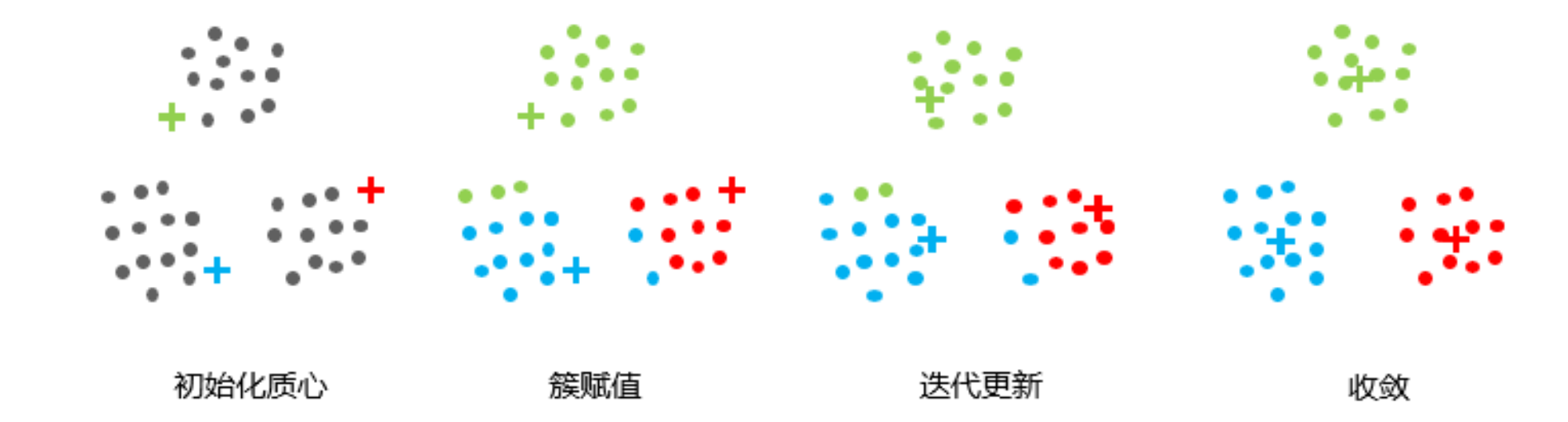
算法流程:
- 选择K个点作为初始质心。 (簇的质心必须小于训练数据点的数目)
- 将每个点指派到最近的质心,形成K个簇。(遍历所有数据点,计算所有质心与数据点之间的距离,簇将根据与质心的最小距离而形成)
- 对于上一步聚类的结果,进行平均计算,得出该簇的新的聚类中心。 (迭代地将质心移动到一个新位置。取一个簇的数据点,计算它们的平均值,然后将该簇的质心移动到这个新位置。对所有其他簇重复相同的步骤。)
- 重复上述两步/直到迭代结束:质心不发生变化。(直到质心停止移动,即它们不再改变自己的位置,收敛。)
肘部法则选择 K 值:肘点之前代价函数的值会迅速下降,肘点之后代价函数的值会就下降得非常慢。一般选择肘点。(比较多次运行K-均值的结果,选择代价函数最小的结果)
- 优点:原理比较简单,实现也是很容易,收敛速度快;聚类效果较优;可解释度比较强;要调参的参数仅仅是簇数K
- 缺点:需要预先指定簇的数量;无法处理异常值和噪声数据;不适用于非线性数据集;高度重叠的数据,那么它就不能被区分;随机选择质心结果不理想;欧几里德距离可以不平等的权重因素, 限制了能处理的数据变量的类型;
二、密度聚类-DBSCAN
Density-Based Spatial Clustering of Applications with Noise
如果 S 中任两点的连线内的点都在集合 S 内,那么集合 S 称为凸集。反之,为非凸集
基于密度的聚类算法:将簇定义为密度相连的点的最大集合,能够把具有足够高密度的区域划分为簇,并可在噪声的空间数据库中发现任意形状的聚类。
使用两个超参数:扫描半径 (eps) 和最小包含点数 (minPts) 来获得簇的数量:
- 扫描半径 eps : 用于定位点/检查任何点附近密度的距离度量,即扫描半径。
- 最小包含点数 minpts :聚集在一起的最小点数(阈值),该区域被认为是稠密的
密度定义为:空间中任意一点的密度是以该点为圆心,以扫描半径构成的圆区域内包含的点数目
将数据点分为三类
- 核心点:在半径Eps内含有超过MinPts数目的点。
- 边界点:在半径Eps内点的数量小于MinPts, 但是落在核心点的邻域内的点。
- 噪音点:既不是核心点也不是边界点的点。
算法流程:
- 将所有点标记为核心点、边界点或噪声点;(对每个点计算其扫描半径Eps的点的集合,如果集合内个数大于MinPts,称为核心点;查看剩余点是否在核点的邻域内,若在,则为边界点,否则为噪声点。)
- 如果选择的点是核心点,则找出所有从该点出发的密度可达对象形成簇; (将距离不超过Eps 的点相互连接,构成一个簇)
- 如果该点是非核心点,将其指派到一个与之关联的核心点的簇中;
- 重复以上步骤,直到所点都被处理过
三、层次聚类
层次聚类假设簇之间存在层次结构,将样本聚到层次化的簇中,属于硬聚类。(硬聚类:一个样本只能属于一个簇,或簇的交集为空集;软聚类:一个样本可以属于多个簇,或簇的交集不为空集)
3.1 分裂聚类(自上而下)
开始将所有样本分到一个簇;之后将已有类中相距最远的样本分到两个新的簇;重复此操作直到满足停止条件;得到层次化的类别
3.2 聚合聚类(自下而上)
开始将每个样本各自分到一个簇;之后将相距最近的两簇合并,建立一个新的簇;重复此操作直到满足停止条件;得到层次化的类别
聚类的评价指标
-
均一性:
类似于精确率,一个簇中只包含一个类别的样本,则满足均一性。也可以认为是正确率(每个聚簇中正确分类的样本数占该聚簇总样本数的比例和) -
完整性:
类似于召回率,同类别样本被归类到相同簇中,则满足完整性;(每个聚簇中正确分类的样本数占该类型的总样本数比例的和) -
V-measure:均一性和完整性的加权平均( 𝛽 默认为 1)
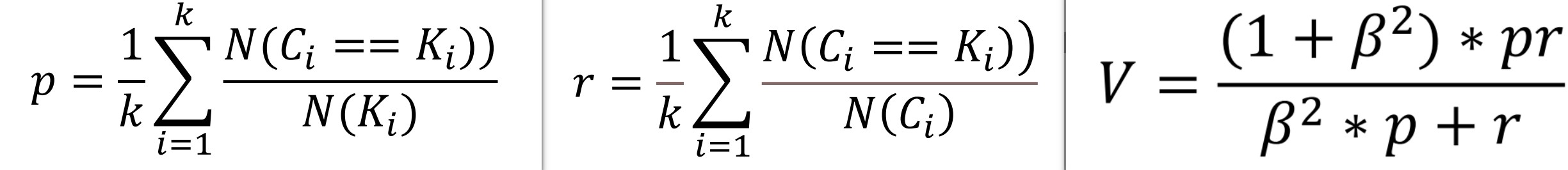
-
轮廓系数:越接近 1 表示样本
聚类越合理;越接近-1,表示样本 应该分类到另外的簇中;近似为 0 ,表示样本 应该在边界上。 簇内不相似度:计算样本𝑖到同簇其它样本的平均距离为𝑎(𝑖),应尽可能小。簇间不相似度:计算样本𝑖到其它簇𝐶𝑗的所有样本的平均距离𝑏𝑖𝑗,应尽可能大。 -
调整兰德系数 Adjusted Rnd Index: ARI 取值范围为
,值越大意味着聚类结果与真实情况越吻合,衡量的是两个数据分布的吻合程度
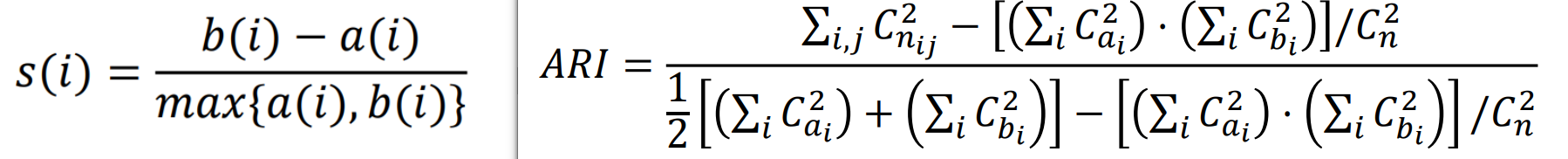
使用场景
医疗:使用聚类算法来发现疾病;市场细分:了解用户群,然后对每个客户进行归类;金融业:观察到可能的金融欺诈行为;搜索引擎:聚类的相似结果;社交网络:给朋友进行分组
市场细分、文档聚类、图像分割、图像压缩、聚类分析、特征学习或者词典学习、确定犯罪易发地区、保险欺诈检测、公共交通数据分析、IT资产集群、客户细分、识别癌症数据、搜索引擎应用、医疗应用、药物活性预测