关联规则
Association Rules
反映一个事物与其他事物之间的相互依存性和关联性。两个或者多个事物之间存在一定的关联关系,那么,其中一个事物就能够通过其他事物预测到。
(可以看作是一种IF-THEN关系)
关联规则概述
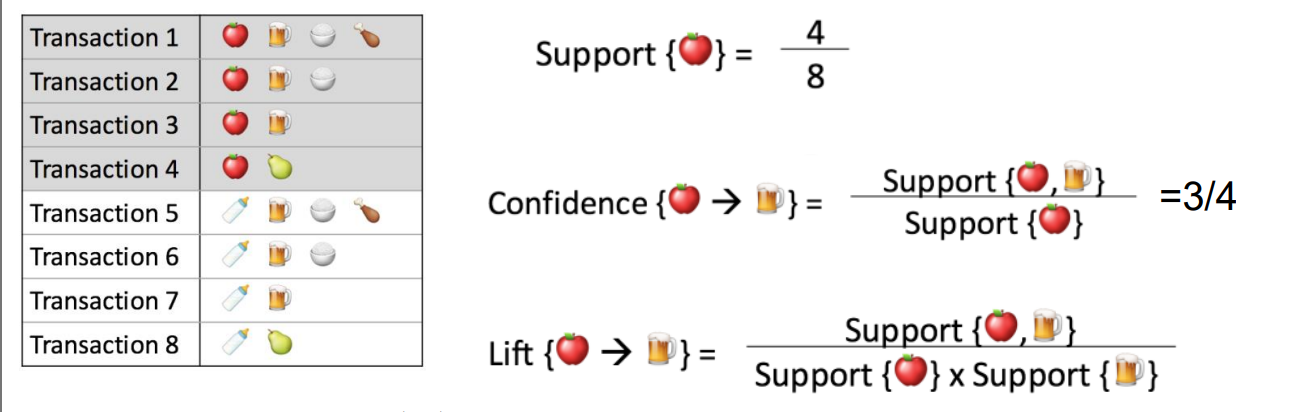
- 置信度:购买了A商品后,还会有多大的概率购买B商品。
- 支持度:指某个商品组合出现的次数与总次数之间的比例,支持度越高表示该组合出现的几率越大
- 提升度:提升度代表商品A的出现,对商品 B的出现概率提升了多少
一、Apriori 算法
利用频繁项集生成关联规则。
频繁项集:支持值大于阈值(support)的项集,频繁项集的子集也是频繁项集。(如果某个项集是频繁的,那么它的所有子集也是频繁的)
算法流程:
- 扫描整个数据集,得到所有出现过的数据,作为候选频繁1项集。k=1,频繁0项集为空集。
- 挖掘频繁k项集
- 扫描数据计算候选频繁k项集的支持度
- 去除候选频繁k项集中支持度低于阈值的数据集,得到频繁k项集。如果得到的频繁k项集 为空,则直接返回频繁k-1项集的集合作为算法结果,算法结束。如果得到的频繁k项集 只有一项,则直接返回频繁k项集的集合作为算法结果,算法结束。
- 令k=k+1,转入步骤2
二、FP-Growth 算法
Frequent Pattern Growth
对Apriori方法的改进。生成一个频繁模式而不需要生成候选模式。采用分治策略:将提供频繁项集的数据库压缩到一棵频繁模式树(FP-Tree),但仍保留项集关联信息。
数据库使用一个频繁项进行分段。这个片段被称为“模式片段”。
频繁模式树:由数据库的初始项集组成的树状结构。 FP树的目的是挖掘最频繁的模式。FP树的每个节点表示项集的一个项。
根节点表示null,而较低的节点表示项集。在形成树的同时,保持节点与较低节点(即项集与其他项集)的关联
构造的基本流程:
首先构造FP树,然后利用它来挖掘频繁项集。在构造FP树时,需要对数据集扫描两遍,第一遍扫描用来统计频率,第二遍扫描至考虑频繁项集
该算法和Apriori算法最大的不同有两点: 第一,不产生候选集;第二,只需要两次遍历数据库,大大提高了效率。
优点:与Apriori算法相比,该算法只需对数据库进行两次扫描;不需要对项目进行配对,因此速度更快;数据库存储在内存中的压缩版本中;对长、短频繁模式的挖掘具有高效性和可扩展性。
缺点:FP-Tree比Apriori更麻烦,更难构建;可能很耗资源;当数据库较大时,算法可能不适合共享内存